Auto-validating JSON with optional documentation
The idea is to have one of the nodes documenting the structure of the rest of them and to have the ability to write textual documentation for the values.
The node "schema?" is used to introduce this structure as a top-level node. The contents of the schema have keys in the form "key? The documentation is here", where the ? sign plays the role of a separator but also says something about the requirement for a key or value’s presence.
key!=> key must be presentkey?=> key is optionalkey+=> value must be non-null, and in the case of arrays it must have alength>0key*=> value may be null
"key", "key!" and "key+" are shorthand for "key!+",
"key?" and "key*" are shorthand for "key?*",
Any value is accepted and documents the type of the value: "", 0, 0.0, true, [], {} etc.
""=> any stringinteger value = 0,value > 0orvalue < 0=> integer number, positive only, negative onlydouble value = 0.0,value > 0.0orvalue < 0.0=> double number, positive only, negative onlyboolean value = true or false=> booleanarray value = [],array value = [value1, value2..]=> any array, or array containing elements in the form of eithervalue1orvalue2(nested specification)object value = {},object value = { "key" : value, ... }=> any object, or object with given schema (nested specification)
No constraints can be set on the order of elements.
Example:
{
"schema?": {
"title! This is shown in the window's titlebar" : "",
"count! The number of things" : 1,
"price! The price in USD" : 1.0,
"head? Optional tag with metadata" : {
"script? One or more script elements" : [{
"source! Each one with a source string" : ""
}],
"meta! Array of metadata strings with at least one element" : [""],
"style!* Any array, even empty one" : [],
"what? Optional, any array" : []
},
"body! Main content" : {
"div? Any number of divs": [],
"span?": []
}
},
"count" : 5,
"title" : "JSON",
"price" : 4.5,
"head" : {
"meta" : ["data"],
"style" : [],
"script" : [{
"source" : "http://...js"
}, {
"source" : "spdy://...dart",
"type" : "text/dart"
}]
},
"body": {
"div" : []
}
}
This also has the advantage of being valid JSON, after all. It can be a separate document used to validate objects passed over the wire, or included inline in e.g. a configuration file. And even if a JSON parser is not validating against the "schema?" the rest of the data is still usable.
Plus, you get comments in configuration files (because JSON does not allow comments..).
Static analysis screenshot
Apple seems to make good GUIs and recently it makes compilers too, and IDEs of course.
Actually I don’t have a mac, never saw XCode, and never used CLang (yet).
But this makes me want them all:

Remember, this is primary a C compiler! I saw few static analysis on C.
And then… just look, it draws a diagram. Mmm… arrows!
Good work!
Old: RAII Obliterator Pattern
I implemnted an obliterator for C#. It works around this problem:
foreach (var item in list) if (item == "two") list.Remove(item);
System.InvalidOperationException: Collection was modified;enumeration operation may not execute.
The new version of the code is one line longer:
using (var obliterator = Obliterator.From(list))
foreach (var item in list)
if (item == "two")
obliterator.Remove(item);
The Obliterator class :
/* This program is free software. It comes without any warranty, to
* the extent permitted by applicable law. You can redistribute it
* and/or modify it under the terms of the Do What The Fuck You Want
* To Public License, Version 2, as published by Sam Hocevar. See
* http://sam.zoy.org/wtfpl/COPYING for more details. */
using System;
using System.Collections.Generic;
namespace Obliterator
{
public class Obliterator<T> : IDisposable
{
ICollection<T> collection;
List<T> toRemove;
public Obliterator(ICollection<T> collection)
{
this.collection = collection;
toRemove = new List<T>();
}
public void Remove (T item)
{
toRemove.Add(item);
}
public void Dispose()
{
foreach (var item in toRemove) collection.Remove(item);
}
}
public static class Obliterator
{
public static Obliterator<T> From <T> (ICollection<T> collection)
{
return new Obliterator<T> (collection);
}
}
}
Gnome/Ubuntu NIH syndrome?
There are at least 3 times when Ubuntu/Gnome teams* bit my user experience by:
– pushing alpha-quality technology
– taking a year to deliver a stable one
– just so that it can match a previous offer.
First: Totem
When I first tried it, it didn’t manage to play anything. When it did, it didn’t had subtitles. Or sound. Or it crashed. Or it crashed Nautilus. Or the browser.
However the Gnome Desktop kept on shipping it, even if 90% of people were using mplayer or xine or vlc. It doesn’t even matches these today, but I can call it stable. Why did they spent that much resources when they could have taken an existing, proven, technology?
Second: Network Manager
Ok, this is sad. Network manager started as an wifi deamon with a usermode icon panel. It didn’t even “speak” wpa_supplicant. Because of the deamon you cannot use wifi-radar an other decent solution. Even hamachi choked with it, because every new connection it sees, it tries to manage.
After one year of NM 0.6, the next version seems a little bit better. It even knows ppp and stuff. But the year with the network-manager 0.6 deamon, with prays for connections, I will never forget..:(
Third: Pulseaudio
First, I don’t even understand what’s that. From my point of view, it’s the thing that stops Audacity from working. And you cannot disable it (I mean, it was hard to find out it existed..)
Basically it locks your soundcard so that anybody should play through pulseaudio. Why the hell would something like that be pushed, along with programs known not to work with it??
I am beginning the wait for another year for a mature pulseaudio or a Gnome/Ubuntu Audacity replacement. “Not invented here” its the oposite of collaboration and hurts other OSs projects.
All these (3) technologies exist because of the Gnome desktop and the way it pushed them. With that “one-year-to-get-decent” policy, they would have failed in infancy.
Is this a bad thing?
update 05/07/2009: i reinstalled PulseAudio while trying to get my bluetooth headset to work (it didn’t). And now I am exposed to a ‘new’ bug, from 2008: I only hear static.
*Ubuntu/Gnome teams: what’s the relation between them?XAML vs MXML (part 1)
Lately I have accepted a job involving WPF (Windows Presentation Foundation) and all the .net 3.5 nastiness.
I have a little previous exposure on Flex (MXML) and that only kick-started me to write a(nother) markup language for Gtk+.
It is only now that I came to reckon what XAML is about. And thought you might want to know how it stacks agains Flex, too.
Before going to code and charts, let me tell you that Microsoft’s offer is far more spreaded that Adobe’s:
Abobe Flex was just the flash plugin for “stage”-oriented advertising and online games, which later got widgets (the Flex SDK) then strong-typeness (ActionScript 3), and now tries to conquer the desktop world with Adobe AIR, which is a standalone runtime that gives access to local files.
The flash player is now a full-blown virtual machine, with a garbage collected, strong-typed language, with access to all the graphic features flash already has and since version 10, access to 3D features.
Microsoft has a very long history of dominating the desktop (Win32 hacks were common-knowledge for 15+ years), then switched to a “bytecode”-like technology which was running against the same Win32 platform widgets (.NET Windows.Forms).
Much more later they introduced this XAML markup (plus a widget toolkit refactoring – WPF) and implemented something for Firefox, something less for MacOS, helped some more the Novell Linux guys implementing even less on Linux (Moonlight)… and are generally heading towards RIA.
So now Microsoft offers full-blown desktop applications only for Windows, XBAP (WPF browser applications) for Firefox and IE but only on Windows, Silverlight applications on Windows and MacOS, and Moonlight on Linux (see above).
What is interesting is that if you compare the Silverlight 2 browser plugin vs a WPF application shows that the former cannot do networking using binary protocols, and cannot do accelerated 3D, both of which Flash/Flex do. So there should be no ‘browser plugin is limited’ mindset, but there is.
That is, the history of desktop-to-web transition is reversed for the two players (MS and Adobe).
(The good part from this race is that the old .res/.rc are ditched now, the macros from MFC are less and less used, and spaghetti code generated by Visual Studio.NET xxxx interface designers is now history (I am looking at you, Java!). Long live Application Markup!
Markup Comparison
So basically this is a comparison of the ‘markups‘ named used in Silverlight and WPF (XAML) and the one used in Flex and AIR (MXML), but also of a couple of other features of the platforms.
But how is this markup made? is it something like HTML DOM + JS? something like Mozilla’s XUL? Something like OpenLaszlo?
No. This is where MXML and XAML are alike: they are unlike any of the above.
What they do have in common is:
- tags are (usually) classes
- attributes are properties (fields with automatic getter and setter method call)
- the root tag of the XML is the base class you’re inheriting
- all other tags are instances that are added up to the parent container
- both use xml namespaces in a similar way (although the URL schemes are different), to specify that the name of a class belongs to another AS3 package or C# namespace(s)
For example, this is the minimum source code for an application in Flex:
App.mxml
<mx:Application xmlns:mx="http://www.macromedia.com/2003/mxml" name="App"/>
And in WPF:
App.xaml
<Application x:Class="MyNamespace.App" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" />
One of the first differences is that XAML seems to need 2 xml prefixes: one for the Application and other tags, and a special one for meta-attributes specific to xaml. That, is ‘x:Class‘, is not an attribute of the Application class, but a meta-attribute valid only on the first tag.
The class name includes the namespace definition.
Flex, apparently, simply uses name, an existing attribute which is present on all UI components, to give the class name. But if you’re not stopping at generating classes with Flex Builder but code your own by hand, you’ll notice that in fact the file name is the name of the class, and the ‘name’ attribute is just run-time information (i.e. exactly the value of the ‘name’ property). Even more, the whole subdirectories path represents the package in which the class resides.
Including actual code
So far so good, you can define your application or another object like this. But how does one include ActionScript code (for MXML) or .NET code (for XAML) to.. actually accomplish something?
In MXML’s case, there is a ‘special’ tag in the mx namespace: <mx:Script> which accepts either direct text content (usually written as a CDATA section) or you can use <mx:Script source=… to specify a file from where the code should be included at compile time. Notice that Script is not actually an object that is added to the UI of the application, but a specially-handled tag.
<mx:Application
xmlns:mx="http://www.macromedia.com/2003/mxml"
name="App">
<mx:Script>
<![CDATA[
//code here
]]>
</mx:Script>
</mx:Application>
In XAML, the preffered way is code behind. You have your App.xaml file automatically associated with App.xaml.cs if the following apply: the .cs file (or .vb) defines the same class in the same namespace, the class in the .cs file is ‘partial’, and both are included in the files to be compiled list of Visual Studio. That is, automagically:)
public partial class App : Application
{
//code here
}
XAML’s x: prefix also includes an <x:Code> tag (notice that it’s in the XAML-specific namespace) but its use is highly discouraged by Microsoft.
--
This post was only a warm-up (for you, for me) to give the general impression of how the two technologies are similar a bit of their differences.
The part 2 will continue to explore all the features of these two Application Markups.
JavaFX: it’s JAVA!
Edit (relevant quote):
When asked why developers and authors would want to choose JavaFX over other tools, such as Flex or Silverlight, Octavian summed it up in one word: Java
Before jumping there, remember: just because you can tell entire corporates that this is the ‘next best thing’, it doesn’t mean people will use it!
Just think ActiveX and their banishment from the Internet..,or, wait, you can think of the water applet!
Pointless update
So.. I needed to re-cap a never-learned science, the computer one.
You see, when I joined a computer science university, I had no “official” CS background (math high-school, yadda-yadda).
I did had a computer at home in highschool – which allowed me to poke around with some ‘exotic’ VGA poking.. but never got into backtracking or other stuff my friends from CS highschool got.
Then, just when the 3rd year in university got to those subjects, I was _so_ employed I haven’t had the time to.. you know.. think before the exams.
So I bought some books now, that I am old enough to afford myself shopping from amazon (heh):
– the algorithm design manual – which I favoured over ‘CLR’ because everybody said CLR was ‘sooo basic’. Now I have to struggle with my english skills because the ADM is explained in plain english rather than scientific way
– the dragon book – yeah..
– learn to tango with D – the only D book available today (I love reading paper, you know..)
– erlang – the only book to – influenced by my reddit fellows
Soo.. I am planning re-writing gtkaml, the markup for UI that I ripped from my XAML/MXML/XUL experience.
But is it worth it?
I want to:
– stop using libxml2, switch to GMarkup, to minimize dependencies. But GMarkup doesn’t even discern CDATA from regular text (I need that for code in a gtkaml class)
– cleanly separate parsing from semantic analisys (lexing is XML).
– generate native Vala AST instead of text (I currently feed a generated source to the Vala parser)
Again.. why would I do it? It’s my first open-source attempt, I tried to announce it on vala list, I had as little as.. one user, then a couple of _month_ later tried to announce it on gnome-announce.
It seems like nobody’s getting where I’m going or doesn’t want to. Since I have this (mainly MXML) background, I concieved gtkaml as a shortcut for _me_ to learn the _Gtk_ UI widgets and their properties. I used it a couple of times to prototype UI for something that would have been to boring to write in C or in Vala.
I got at maximum 100 downloads per release, starring on gnomefiles and freshmeat. It lowers – the latest version, posted on gnome-announce, had less downloads.
Is it because, not having a well organized parser/code generator, every hacker scares away (from the error messages for example)??
I also get compared with glade/GtkBuilder that often that I explained in a previous post the differences. But still nobody cared.
Can somebody point me their open-source experience? is this normal? (i.e. to have an unique itch and scratch it?)
SQL Dependency Injection
“All problems in computer science can be solved by another level of indirection, but that usually will create another problem.” — David Wheeler, inventor of the subroutine
This is the story of a “framework” that doesn’t exist: SqlDi
Most database frameworks’ authors consider that it is wrong to write SQL in your source code and provide many kinds of wrappers you need to deal with, instead of pure query strings.
Their reasons are along the lines of:
Portability: SQL is not database independent
Sadly, this is true. Although there are ANSI standards – ANSI SQL 99, 2003 etc. – no RDBMS supports all the features from ANSI and most vendors force you to use some of their custom extensions to accomplish things from the standard.
(For example, SQL 2003 introduces ‘window functions’ that could be used instead of the vendor specific ROWNUM, LIMIT or TOP keywords – and the window functions allow you to do even more. Few database systems support SQL 2003 though..)
Abstraction: SQL queries contain details about the storage mechanism
The relational model is a good way of assuring the integrity and non-redundancy of data. JOINs allow you to reverse the normalization process, while keeping the “Single Point of Truth” – storage model. INDEXes allow you to lookup faster.
Having SQL (in your source) that displays all these storage details is bad in practice. Even if your attributes (columns) are not subject to change, the way of retrieving them may be.
For example, if you want to display a (paginated) list of books on a web page, with their authors, a minimal query would be:
SELECT books.title as title, books.date_published as date_published, authors.name as author FROM books INNER JOIN authors ON books.author_id = autors.id WHERE ROW_NUMBER() OVER (ORDER BY books.title) BETWEEN 1 AND 10
This is both an example of SQL that reveals the storage internals and that is not portable (because ROW_NUMBER() is supported by very few ‘chosen’ ones)
Correctness: Query strings are validated only when run against the database
Even if you’re using an editor that knows how to highlight syntax from the SQL strings, you are still prone to mistakes, syntactical or not (e.g. wrong column name).
The usual solution is to write objects that construct your query – here’s an example for Hibernate’s Criteria API
Criteria crit = session.createCriteria(Cat.class); crit.add( Expression.eq( "color", eg.Color.BLACK ) ); crit.setMaxResults(10); List cats = crit.list();
This still fails if the “color” string is mistyped, for example.
SqlDi
The proposed SqlDi solution emphasizes some of the positive things about SQL, while working around the above-mentioned issues.
First let’s talk about the “Domain Specific Language” well known meme – SQL is one of the best examples of DSL around, but suddenly everybody wants to write in lolcode like this:
include StarbucksDSL order = latte venti, half_caf, non_fat, no_foam, no_whip print order.prepare
As opposed to this ruby Starbucks language I found on the web, SQL has proper syntax rules, and everybody knows at least its basics.
So SqlDI will allow you to write a subset of SQL called SqlDi.
But how about the aforementioned Abstraction ?
In order to decouple the storage model from the application query, SqlDi uses a kind of remote-process inversion of control (RP/IoC) pattern where the actual storage-specific part of the query gets injected in your code by the RDBMS process (instead of your code depending on the storage layout).
Here’s an example of the previous query, re-written in SqlDi:
SELECT title, date_published, author FROM books_with_authors LIMIT 1,10
You can already guess the syntax of SqlDi, but I will paste it here anyway:
SELECT attribute_expr [, attribute_expr]* FROM thing [WHERE boolean_expr] [LIMIT n [,m]]
Now how does the ‘thing’ called ‘books_with_authors’ got injected?
Simple, it’s part of the database “configuration file” (the script that creates the schema):
CREATE TABLE authors ( id INTEGER PRIMARY KEY, name VARCHAR(80), birthday DATE); CREATE TABLE books ( id INTEGER PRIMARY KEY, date_published DATE, author_id INTEGER FOREIGN KEY REFERENCES authors(id) ); CREATE VIEW books_with_authors AS SELECT books.title as title, books.date_published as date_published, authors.name as author FROM books INNER JOIN authors ON books.author_id = autors.id;
Now, if some other time you discover that one book can have multiple authors, all you have to do is to re-write the storage-dependent part of the query.
But how does SqlDi provide Portability ?
SqlDi is a parser for a subset of SQL – you have already seen the SELECT statement syntax. The various functions dealing with numbers, dates and strings, even the operators (such as string concatenation) are defined one way or another in SqlDi and translated into the native dialect.
For example, the LIMIT keyword is translated into ROWNUM, LIMIT, TOP or ROW_NUMBER() depending on the used database.
This translation is accomplished in two steps:
- First, the query is tokenized and parsed, and an object which represents the root of the Abstract Syntax Tree is constructed.
- Second, the AST spills out the native dialect – based on some form of run-time pluggable dialect writers (plus ‘drivers’)
In this way you’ll never need to change the “SELECT x FROM y WHERE …” from your source, even if you change the used database. (You do, however, need another schema creation script).
Yeah, but how about the compile-time Correctness ?
This is the most interesting part.
SqlDi is implemented in D (because I don’t know LISP), and the first step (parsing) is accomplished at compile-time, through the use of mixin() statement. The output of parsing is code, like this:
SqlDi.Select ( "books_with_authors", null /*the where clause*/, 1, 10 );
For example, if you have WHERE name LIKE ‘Richard %’, instead of a null you will have SqlDi.Like ( SqlDi.Column(“name”), “Richard %” ) – where “SqlDi” is the package name.
Of course you could write this yourself if you are a hardcore SqlDi user;)
Conclusion
To summarize what we achieved:
- you can write SQL in your source code,
- it will be database independent and
- you will get compile-time syntax checking
- bonus points: the DBA will become your best friend
What we didn’t do:
- no object mapping was even considered
- we didn’t enter into details of INSERTs and UPDATEs
- SqlDi does not exist
what gtkaml is not
Updated nov. 2010
I noticed that the first reaction when people hear about gtkaml is “But GtkBuilder/glade already does this!” or “How is gtkaml better than glade?” or something along these lines.
Let me put this straight: there is no resemblance between gtkaml and glade (other than using markup). None. They are not mutually exclusive, and do not do the same thing.
You can tell this by looking at them!
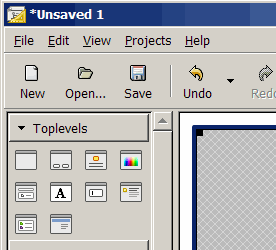 |
 |
what they are
First, libglade is a library (and GtkBuilder comes bundled with Gtk+). You link against it and it parses your UI markup at runtime.. Glade is also a visual editor for that markup.
On the other side, gtkaml is a preprocessor. Your markup becomes code, Vala code, which and eventually becomes static C code.
language bindings
glade and GtkBuilder can be used from many different programming languages.
gtkaml is only available for Vala. However, libraries created with Vala can be used from any language.
run-time vs compile-time
GtkBuilder and glade make it possible to change the UI markup without compiling. This is because they call Gtk+ functions from libgtk, functions determined at runtime.
gtkaml only knows what you meant when compiling – it uses Vala’s AST to do this. You have to recompile to change the UI, therefore.
syntax
GtkBuilder and glade have their own markup which is verbose and usually must be written by means of an interactive tool (glade).
Every new Gtk property or class must have Glade/GtkBuilder support for it to work.
gtkaml simply maps tag names to classes and tag attributes to properties/fields/signals.
signals
Because of the run-time capabilities, GtkBuilder and glade require you to export your signal handlers from your own executable, like an .so/.dll does, or to write GtkBuilderConnectFunc’s for them.
gtkaml simply uses Vala’s signal .connect() which translates into g_signal_connect () function calls.
widget referencing
GtkBuilder requires calling gtk_builder_get_object (“by name”) to get a reference to a widget. Similarly, glade has lookup_widget (“by name”).
gtkaml optionally lets you declare widgets as public or private fields, so you can use them directly.
using custom widgets
glade requires specific code to instantiate custom widgets (set_custom_handler ()). GtkBuilder requires the widgets to implement GtkBuildable (which is a Good Thing).
gtkaml only needs them widgets to be compatible with the parent add method (wether is Container.add or something else).
Update: They don’t even have to be widgets, they can be Clutter actors or some business model objects.
creating custom widgets
GtkBuilder or glade do not have support for creating custom widgets.
gtkaml does only this. It creates custom (composite) widgets.
other than Gtk
glade and GtkBuilder are Gtk+ specific.
gtkaml can now accomodate any library that has a Vala vapi file (such as Clutter, Hildon, MX really, any) – you only have to point out in an .implicits file the methods used to add childs to a container.
Conclusion: use GtkBuilder if you need to change the GUI without recompiling. Use gtkaml to write custom composite widgets (with Vala code within) or use a gtkaml with the MVC pattern to separate view from behavior.
C++ and C++ TR1 (Technical Report 1)
In this post I will assume you’re familiar with other languages like Java and C#, which are OO languages, and you start to learn the ‘multi-paradigm’ C++. Yeah, you couldn’t be that guy, could you.
So you already know the syntax.. so quick, let’s write classes!
We’ll start with a ‘bitmap’ that supposedly encapsulates a bitmap image, allocating memory at construction and freeing it at destruction:
/* bitmap.h */
#include <string>
class bitmap
{
unsigned char *data;
public:
bitmap(std::string path);
~bitmap(void);
};
/* bitmap.cpp */
#include "bitmap.h"
bitmap::bitmap(std::string path)
{
//allocate memory
data = new unsigned char [1024];
//read data from path
//parse it as an image
}
bitmap::~bitmap(void)
{
//free the memory
delete [] data;
}
Now that’s pretty simple and obvious, given that details about reading/parsing the bitmap are left out.Let’s see how we can use this class; we can allocate a bitmap object on heap like this:
/* main.cpp */
#include "bitmap.h"
int main (int argc, char * argv[])
{
bitmap *icon = new bitmap ("./icon");
}
Oops.. not good, our destructor doesn’t get called. We have to manualy call delete icon so that it calls its delete [] data.
Hmm.. ugly.
But we do know that desctructors are automatically called when an auto variable gets out of scope and so we do this:
bitmap icon = bitmap ("./icon");
Bummer! this time the destructor is called twice! Obviously, it fails the second time:(
The reason is that we weren’t aware that the default assignment operator is called in what we thought was an initializer (that ‘=’ that stands between the object and the constructor call).
This is actually one of the reasons most C++ code reads like:
bitmap icon("./icon");
The other is performance.
(yeah, event a simple int f = 0; gets obfuscated to int f(0); which looks like a goddamn function call)
Introducing auto_ptr<T>
We can further get rid of: the stars ‘*’ and the destructor by declaring the data to be an auto_ptr:
#include <string>
#include <memory>
using namespace std;
class bitmap
{
auto_ptr<unsigned char> data;
public:
bitmap(string path);
};
#include "bitmap.h"
bitmap::bitmap(string path)
{
data = auto_ptr<unsigned char> (new unsigned char [1024]);
}
auto_ptr is a class that wraps a pointer. Its instance being used without dynamic allocation, the instances are freed (after being destructed) when they are out of scope.
This simply allows the ~auto_ptr () destructor to call ‘delete’ on the wrapped heap object just like with an auto object: when it gets out of scope.
It allows us to write code like this – once again:
bitmap icon = bitmap ("./icon");
and like this:
data = auto_ptr<unsigned char> (new unsigned char [1024]);
That is because the assignment operator of the auto_ptr transfers ownership of the wrapped object, NULL-ing the old reference, and because the right-hand expressions in the above two examples are not used further in the code.
You’re still fucked up if you write:
bitmap largeicon = icon;
since the right-hand object is left with a NULL reference!
Introducing shared_ptr<T>
shared_ptr is a class that boost provided long time ago, and now will be part of the upcoming C++ standard (C++09 probably, but currently named C++0x).
This is, one way or another, already supported in the upcoming Visual C++ 9 SP1 (today as a beta feature pack) and also in GNU g++ 4.x
The simple fact that this feature, now in the standard, can be provided by a library tells something about the power of C++. Unfortunately, the fact that the boost implementation is unreadable tells another thing – about C++ compilers. (to think about it, what other languages have as many compilers – and compilers’ problems – as C and C++?)
Basically, shared_ptr is counting the references to a pointer, and, when copied, increments the references, and when destructed, decrements their number. Finally, when no more references exists, it calls ‘delete’.
So our pointer-free source (sic!) becomes:
#include <string>
#include <memory>
using namespace std;
using namespace tr1;
class bitmap
{
shared_ptr<unsigned char> data;
public:
bitmap(string path);
};
#include "bitmap.h"
bitmap::bitmap(string path)
{
data = shared_ptr<unsigned char> (new unsigned char [1024]);
}
#include "bitmap.h"
int main (int argc, char * argv[])
{
bitmap icon = bitmap ("./icon");
bitmap largeicon = icon;
}
If read up until here, you have just seen the way to aquire the memory resource on instantiation, so that you don’t need to manage it’s release.
TR1 has other new things too.. next time we’ll check on the <functional> classes function, bind and result_of.
(to compile the above in g++ 4.x, use #include <tr1/memory> and using namespace std::tr1;).
