attribute values in gtkaml
Rule of the thumb: when you don’t enclose your attribute values in {}’s, something magic is going to happen.
That is because gtkaml tries to make your life easier. Let’s take the first example,
Properties
<Window title="my window" type="{WindowType.TOPLEVEL}" ...[/sourcecode]
The difference between using and not using curly braces is obvious: if you use {}, you get to write a valid <b>code</b> expression. Otherwise, gtkaml tries to guess a literal for you: in this case, title being a <b>string </b>property, the value <<my window>> gets translated to <<"my window"">> in Vala.
This would be the equivalent of <b>title='{"my window"}'</b> (you have to use the alternate single-quotes of xml for this).If the property is <b>bool</b>, you get exactly the "false" or "true" literal, and if the property is an <b>integer</b>, the same.
Actually, whatever the property is that is not a string, you get what you typed - the "magic" happens only for string properties.
Alternate 'spellings' for the code above are possible, along the lines of:
<Window>
<title>my window</title>
<type>{WindowType.TOPLEVEL}</type>
</Window>
or if your value contains invalid xml characters:
<title><![CDATA[my window >= your window]]></title>
Signals
<Window destroy="{Gtk.main_quit}" />
<Window delete_event="Gtk.main_quit()" />
<Window delete_event="{ widget => { Gtk.main_quit (); }" />
The difference is that the first is an expression of type “function” (an expression that returns a function), while the second is executable code. The generated Vala source is like this:
//with curly braces:
this.destroy += Gtk.main_quit;
//without curly braces
this.delete_event += (target, event) => { Gtk.main_quit(); };
//third way - just like the first
this.delete_event += widget => { Gtk.main_quit (); };
Second, the value without curly braces does the “magic” of creating an anonymous function and to automatically fill the signal parameters for you. This can be helpful if you want to write short executable code in a simple attribute; otherwise you can write a ‘full-blow’ function body in a CDATA section:
<Window>
<delete_event><![CDATA[{
widget => {
Gtk.main_quit ();
}
}]]> </delete_event>
</Window>
Notice, however, that you have to use curly braces two times: one for the method body, the other for gtkaml to know not to do any ‘magic’.As you can see, no matter how you specify the signal, gtkaml adds the last “;”.
Construct
gtkaml 0.2 (svn version as we speak) features two new properties, named gtkaml:construct and preconstruct. This is because gtkaml creates the class construct for you (where it sets up the attributes, adds children to containers etc), but you might need to add yourself code there. You can use gtkaml:preconstruct and gtkaml:preconstruct on all tags:
- preconstruct is executed just after the object is instantiated, before setting the other properties
- construct is executed just before the object is added to it’s parent container
As a side effect, the root tag has ‘preconstruct’ executed before all others preconstructs and the ‘construct’ after all other constructs.
These attributes are to be used exactly like a signal: you write code, and you have the “target” parameter (the widget)
In the case of using {}, you can directly assign an existing function that receives a widget or void as parameter, or write a lambda expression in-place.
Example:
<Window
class:preconstruct="{view_init}"
class:construct="post_init(target)" />
As with the signals above, the first attribute simply sets “view_init” as the method to be called, and the second method actually wraps the call into a lambda function defined like target => { post_init (target); };
There isn’t much to do with the target parameter in this example: you can always use this. instead. But it may be very useful if you want to modify an unnamed widget.
Layout: Windows, Java and “Others”
99% of visual application developers use some tool to draw/drag/resize or even dock/anchor their child widgets visually.
One of the first tools I used myself is Resource Workshop from Borland:
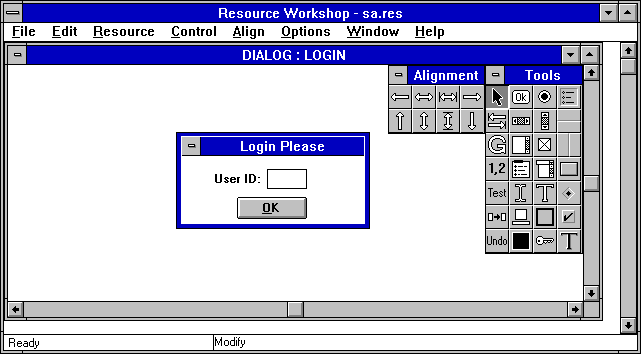
Yes, the Win16 version:)
Anyway, it’s a visual WYSIWYG editor. Just like the current Microsoft tools from .NET (now they are integrated in the development environment). One difference is that instead of editing a simple .res/.rc file, now they edit a partial C# class)
Why partial? because initially it was editing your class. And since the code generated was awful, you had to scroll down (or collapse) entire pages of code before getting at your stuff.
Here’s how some of the ‘partial’ code looks:
this.label1 = new System.Windows.Forms.Label();
this.textBox1 = new System.Windows.Forms.TextBox();
this.button1 = new System.Windows.Forms.Button();
this.SuspendLayout();
//
// label1
//
this.label1.AutoSize = true;
this.label1.Location = new System.Drawing.Point(46, 14);
this.label1.Name = "label1";
this.label1.Size = new System.Drawing.Size(46, 13);
this.label1.TabIndex = 0;
this.label1.Text = "User ID:";
//
// textBox1
//
this.textBox1.Location = new System.Drawing.Point(98, 12);
this.textBox1.Name = "textBox1";
this.textBox1.Size = new System.Drawing.Size(51, 20);
this.textBox1.TabIndex = 1;
//
// button1
//
this.button1.Location = new System.Drawing.Point(66, 65);
this.button1.Name = "button1";
this.button1.Size = new System.Drawing.Size(75, 23);
this.button1.TabIndex = 2;
this.button1.Text = "&OK";
this.button1.UseVisualStyleBackColor = true;
//
// Form1
//
this.AcceptButton = this.button1;
this.AutoScaleDimensions = new System.Drawing.SizeF(6F, 13F);
this.AutoScaleMode = System.Windows.Forms.AutoScaleMode.Font;
this.ClientSize = new System.Drawing.Size(206, 104);
this.Controls.Add(this.button1);
this.Controls.Add(this.textBox1);
this.Controls.Add(this.label1);
this.Name = "Form1";
this.Text = "Login Please";
this.ResumeLayout(false);
this.PerformLayout();
Notice the number of integer literals used to represent screen coordintates: it can get better, if you use anchors, but still the default layout is ‘absolute’. And this is not resize-friendly (actually these kinds of dialogs always have resize disabled;))To make up for the DPI change in today’s monitors/resolutions, .NET provides a property named “AutoScale” for dialogs, with values “Font” or “DPI”. That is, keep your design absolute at this font/dpi and I will compute for you another size at the client’s font/dpi settings…
Java got further and reckon’d the need of relative layouts: the choices are many, BoxLayout, GridLayout, SpringLayout, FlowLayout and last but not least, GridBagLayout. None of them was usable for any serious stuff (oh, I forgot the ‘null’ layout) but GridBagLayout.
This layout is so complex that maybe one may think that nested GridBagLayouts approach the Turing-completeness of PostScript/PDF (they don’t). Here’s an example of parameters one must specify to add a component to a container that has the GridBagLayout:
public GridBagConstraints(int gridx,
int gridy,
int gridwidth,
int gridheight,
double weightx,
double weighty,
int anchor,
int fill,
Insets insets,
int ipadx,
int ipady)
Oh well. You have to call that constructor for each child add..Actually it does not resemble PS/PDF in any way, on second thought: it is HTML table layout or CSS layout (whichever, they are equally stupid).Ok, what did Others?
Well, others are (at least):
- Qt
- gtk+
- wxWidgets (sortof)
- Mozilla XUL
- Flex
They proved that any layout can be expressed with only three simple constructs: VBox, HBox and Grid!
VBox is for laying childs vertically, HBox is for laying them horizontally, and, if you ever need something like “two HBox’s in a VBox” and you need each child of a HBox to be aligned with the same child in the other HBox, then you actually need a two-row Grid;)
Don’t believe it? just look at the source of the XUL Mozilla Amazon Browser (does it contain any integer literals?)
how gtkaml works
If you are writing something based on GTK+ / GObject then you should be interested by this:
- Vala is a very productivity-boosting language based on GObject OOP-ness, which translates to C and therefore can export GObject classes and interfaces from shared libraries.
- gtkaml is a thin SAX Parser on top of Vala that allows you to write XML user interface descriptions
This is how a minimal Vala class described with gtkaml looks like:
<VBox class:name="MyVBox"
xmlns="Gtk" xmlns:class="http://gtkaml.org/0.1">
<Label label="Hi_story"
expand="false" fill="false" padding="0" />
</VBox>
This code creates a class named MyVBox that extends VBox and contains a Label. The label has the value “History”, it does not expand or fill its box and is not padded.Easy, no?
But GtkLabel doesn’t have expand, fill, or padding properties! I hear you say. Yes, but the pack_start () method has them as parameters.
Which leads us to the first subject:
Container Add Methods
gtkaml uses a file named implicits.ini to determine which containers have which add methods. This is for “implicit” decisions it makes based on your UI layout.
For the example above, it simply finds this:
[Gtk.Container] adds=add_with_properties [Gtk.Box] adds = pack_start;pack_end;pack_start_defaults;pack_end_defaults
This simply lists all the functions that one can use to add widgets to a Box and to a Container. Since VBox is a Box and Box is a Container, gtkaml finds these two entries ‘significant’ and merges them in this order (most specialized first):
pack_start;pack_end;pack_start_defaults;pack_end_defaults;add_with_properties
Then it loops over these methods – in this order – finds the first matching one and ‘picks’ the parameters from the child widget tag: that is, it removes “expand”, “fill” and “padding” from the Label and makes a note to use their value when adding the label in the VBox.
What if I want to use another add method?
Well, in that case simply specify the method’s name as an attribute of the child tag, with the value “true”:
<Label pack_end="true" label="Hi_story"
expand="false" fill="false" padding="0" />
Creation methods
In this same example we notice that the label contains an underscore: this is intended to show up as a “mnemonic” (an keyboard shortcut) or simply as “History”.
Looking again at the GtkLabel documentation we notice that the only ways to get a mnemonic is to use either gtk_label_set_text_with_mnemonic () or gtk_label_new_with_mnemonic (). But since gtkaml can only help you with public fields, properties and signals, and not with function calls, how does one specify a mnemonic?
The answer is that you can select a “creation method”, and gtk_label_new_with_mnemonic () is not an ordinary function but a creation method. That is, a method that does not require the object as the first parameter but returns a new object.
So simply specify the creation method name as an attribute with a value of “true”: with_mnemonic=”true”.
Wait, but how about the creation method’s parameters? with_mnemonic has one parameter named str..
Well, usually Gtk widgets’ creation methods have their parameters named after the field/property they are initializing. gtkaml recognizes them from the specified attributes.
In this case, though, str is not a field or parameter of GtkLabel. But we know that it actually refers to the label property.
So what gtkaml does is to specify, again, in implicits.ini, the attributes that will go as parameters to the creation method:
[Gtk.Label] new = label new.with_mnemonic = label
So the code becomes:
<Label pack_end="true" with_mnemonic="true" label="Hi_story"
expand="false" fill="false" padding="0" />
That’s it! – more on what gtkaml 0.2 will do for you in a future article.
p.s. as I am writing this, gtkaml was accepted on freshmeat.net! yay!
spam, rant, or code? (all verbs)
(for those who need help deciding)
- Put a link as IM ‘status message’ to my first drawing.
- Then write a rant about OOP.
- Then announce my first software release.
- ??
- Profit!?
developer-friendly distro
(what, no links in this post? but you know what i’m talking about..)
I am currently running Ubuntu, and some months ago used to run ArchLinux. Some year ago I used to manually install everything in slackware, without package dependencies (swaret executed an ldd on the new binaries and searched another package to provide them;)
I quit slackware when, exasperated of building gnome with jhbuild, I tainted it with dropline and no way back was known but fresh install. It was the most developer-friendly distro I had: want to test some new library/compiler or anything? svn co && ./configure && make install and you had it. Same with all bleeding-edge packages.
Next, ArchLinux was a breeze: you did ‘pacman gnome’ (or something) and it listed you everything that will be installed (belonging to the group ‘gnome’). Installing bleeding-edge software in Arch was a 3-choices thing: you either already found the latest version in the testing repository, or you found a PKGBUILD script in the Archlinux User Repository (based on which you built your own package, maybe a new version if you wanted) or, in the worst case, you needed to write the PKGBUILD yourself.
The PKGBUILD was like a 5-liner with package name, version, dependencies and a build () function that did.. svn co && ./configure && make install.
Then there’s Ubuntu, where you can find Anjuta (for example) in Add/Remove Programs :D
Now I need the bleeding-edge glib 2.15.4.
- With Slackware, I would have just installed it.
- With ArchLinux, I would have had to write PKGBUILD files.
- With Ubuntu, I made a ‘dist-upgrade’..
Wanna know how it looks? well, you run gksu update-manager -u and it tells you ‘Ubuntu 8.0.x is available’! Install?
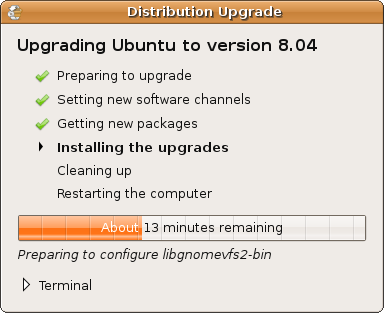
Isn’t it cool? Imagine how would it have been to have a ‘vista.exe’ to download from windows xp and it tells you this: downloading vista – installing vista – cleaning up – restarting the computer
I was able, just like from the livecd, to browse the web while the O.S. was updating. Till it upgraded firefox:D
Actually, restart is required mostly because of the kernel change (some executables won’t play at all).
This is one of the reasons ArchLinux is always releasing a ‘Duke Nukem’ release:
Sadly, Arch will never have a 1.0 release. It is, in fact, canceled. But this is for the best.
We’re changing gears and switching the way we do releases. Going forward, a new ISO will be released with each new kernel version. This will give us an easy milestone for us, and you, to follow.
That is, a new ISO with each ‘reboot required’.
I loove that, and I think the effort put into Ubuntu to ‘upgrade from XP to Vista’ is worth the pain only for a company that provides profession long-term support for the products.
But me, the developer, has to lose. The upgrade to the Alpha4 Hardy Heron made me spend 3 hrs of iwl3945 debugging. And it’s far from solved…
So, next time, pick a developer-friendly release!
*btw, you know what’s new in gnome 2.22? Alt-Shift-Tab for backwards switching of windows! yay!
gtkaml 0.1 released!
Well, actually gtkaml 0.1.0.1…
I had problems with autotools.. my examples installed in the /usr/bin directory – which was uncool.
And the googlecode decided that no release should be deleted – so I bumped the version up and released once again..
Anyway, in case you don’t know, gtkaml is an XML preprocessor that transforms all your container/widget descriptions into Vala. I proposed myself to build this project some time ago.
And now it’s done! Next thing I know, I’ll be that proficient in GTK that I will event start my own Norton-Commander clone in gtkaml + vala!
So here it is, the announce: giocommander will be a NortonCommander clone written in GTK with the new GIO api that’s bundled in GLIB.
The Linux version will be featureful, if you have GVFS installed, and the Windows version will be “O.K”
You know why? Because it’s simpler to develop a software that’s featureful in Linux and crippled in Windows:-P
And if you add enough features, you might end up installing Linux just to get them! (What, you never installed Windows just to get Photoshop or Autocad? Why not the other way?!?)
Ok, jokes aside, let’s get back to the drawing board..
(basic) functional programming in C++
(update: simplified expression)
So I’m (re) learning C++. And would like to point out some functional language features found “out of the box” – although using boost::lambda or boost::bind you could get nicer ones, or waiting for C++0x would be another option…
This came to me while reading the wikipedia article on functional programming , which basically gives this example (in python I think):
# functional style # FP-oriented languages often have standard compose() compose2 = lambda F, G: lambda x: F(G(x)) target = map(compose2(F,G), source_list)
And the tag-line:
In contrast to the imperative style that describes the steps involved in building target, the functional style describes the mathematical relationship between source_list and target.
To begin, let’s have a look at an imperative version that I coded in C++:
vector<string>& imperative_version (vector<string>& source_list)
{
vector<string> *target = new vector<string> ();
string trans1, trans2;
for (vector<string>::iterator item = source_list.begin ();
item != source_list.end (); item++) {
trans1 = G (*item);
trans2 = F (trans1);
target->push_back (trans2);
}
return *target;
}
Pretty long, isn’t it? Besides defining type for the elements of the ‘list’ (I used a vector), and allocating memory, you can see the ugliness of the iterator type and.. well.. the imperative for loop with calls to the F and G functions.What I did was that I shortened everything down to:
vector<string> target = map<string>(source_list, compose (F, G));
What this code does is to call a function named map() that receives a vector and a function, calls the function on each element of the vector and returns a new vector with the results.Exactly like in the functional programming example, the functions F and G are composed so that the actual transformation is target[i] = F(G(source[i])).Let’s look at another example:
vector<int>target_int = map<int>(source_list, compose (len, F));
So, how is this implemented? compose2 is a functor: it is actually an object that has the () operator overloaded. And here’s the class definition for it:
template <typename input_type, typename intermediate_type, typename return_type>
class compose2 {
private:
return_type (*f)(intermediate_type);
intermediate_type (*g) (input_type);
public:
compose2( return_type (*F)(intermediate_type), intermediate_type (*G) (input_type)) :f(F), g(G) {}
return_type operator() (input_type input)
{
return (f(g(input)));
}
};
What it does is that it requires two functions when the constructor is called and, upon calling the () operator, evaluates them.We cannot use compose2 directly without specifying the input type for the G function, the input type of the F function and last, the return type of the F(G()) function.
But we can make the compile infer them by wrapping everything in a function template, that has the ability to better deduce the type arguments:
template <typename input_type, typename intermediate_type, typename return_type>
compose2<input_type,intermediate_type,return_type> compose (return_type (*F)(intermediate_type), intermediate_type (*G) (input_type))
{
return compose2<input_type,intermediate_type,return_type> (F, G);
}
The compose2<>() statement is a call to the compose2’s constructor. It returns a compose2 instance ready to replace a function.
Then there’s the map() function that applies a function to a vector, using the transform() algorithm:
template <typename out_type, typename in_type, typename functype>
vector<out_type>& map (vector<in_type>& in, functype f)
{
vector<out_type> *target = new vector<out_type> (in.size ());
transform (in.begin (), in.end (), target->begin (), f);
return *target;
}
The out_type has to be specified because it cannot be inferred.(tested with MSVC 2005 and g++ 3.4.5 (mingw) and g++ 4.1.5)

Why OOP failed on us
[updated 21 Jan 2008: added more about vala]
[clarification: “us” = those hacking software in their spare time – except web software – and want to ship]

C++ was promising everything, 15 years ago. Over C, I mean.
Everybody started declaring the variables where it crossed their mind, overloading functions and giving default values, and from time to time they played with the class keyword. Oh, and operators, never forget!
When everybody started thinking in classes, they started to play with the template keyword.
Borland seems to have closed the Delphi business but freepascal and Lazarus are still alive nowadays.
In the other news, starting from ’95 there was Java, which was also OOP. The Smalltalk people were not that company-backed to be successful and nobody seemed to write in Objective-C than Steve Jobs for his NeXT computer. Simula.. I never heard of simula!
Then Web started kicking in, and php (3, then 4, then 5), perl, python all came along. Now ruby, and probably the next big interpreted language is right next door.
Then there’s C#. And J#, And F#, never mind VB (.net, not #). All running on virtual machines.
I will make a big step ahead and tell you:
All software on your machine is written in C.*
Or in C++/Delphi, but linked with C libraries.
* not all of it, but 99%
Nobody (that I know) ever downloads a program in python. Never mind Java, C#, or.. hell, desktop applications in PHP:) Even LISP lacks a great compiler – and nowbody downloads “runtime environments“.
This is OOP: no matter how much syntactic sugar you’re pouring into a language, it all boils down to interoperating with existing libraries, linking against them, calling them (and be called) using their calling conventions, registers, stack and even their byte order. OOP is none of these.
What OOP is is virtual tables, polymorphism, closures, multiple inheritance, reusability etcetera etcetera.
But nobody found a way to instantiate a class from a compiled library… It all boils down to processors, Turing/Von Neumann machines and assembler.
You can have this problem solved in two ways:
- write an interpreter in C. This abstracts you from the environment soon enough. Re-invent all the basic functions of your environment in the interpreted language.
- write your own abstraction layer as a runtime environment. You can do whatever you like in that environment, but not outside it. You end up re-writing 50% of the operating systems you’re running on .. in classes.
- use an existing abstraction layer: use C to abstract away from system calls and use something different to abstract you away from C.
C++ did that (the last). The first C++ compiler was a C preprocessor. Because of the operator overloading, function overloading, classes and template crap, it had to do some name mangling, but it did it. Then along came true C++ compilers, then exceptions etc. Nothing was standard anymore, except the extern “C” { directive. It miserably failed to inter-operate with compiled libraries.
Java, C# did the second: they wrote their runtime environment just to cope with portability. Interoperatibility was penalized ( JNI? COM/Interop? ha.. ha.. ). Although calling native libraries was possible, the download for the runtime environment was a show-stopper: nobody wanted your kilobits of C# because of the hundreds megabytes of your supporting virtual machine..
Therefore they are used server-side.
PHP, perl, python, ruby chose the first: interpret for the masses! Basic did that, and it had the advantage of only two datatypes: string or number. But the costs.. Yeah, interpreted languages have their cost, like.. no threading machine – these (multicore) days.. Nobody wants to download perl.exe for their favorite money calculator..
Therefore they are used server-side.
So, what’s left? is winamp made in C? is Total Commander made in C? What about Firefox??
Tell you what: winamp is indeed C. TC is Delphi. and Firefox is XUL+JavaScript+XPCOM, where XPCOM is made in C.
What does C and delphi have in common? No name mangling. Delphi was proprietary, that’s why.. (VB6.0 didn’t have this problem either)
So how do you do to still program OOP and do it in C ? I challange you: http://www.google.ro/search?q=C+oop
All your OOP code could be done in assembler (in C, however, it’s portable)
In the same way. Given that your runtime environment or your interpreter still runs on a Turing machine, the same thing can be done in C. Manually.Well, why would you do that??
Well, you may be Mozilla Foundation and you may be building browsers for all platforms. XPCOM is OO, of course.
Or you may be Jack the coder, and ‘you know jack’ about MacOS X, but would still want to compile there. Oh, and there’s an AI engine you’re doing that needs performance..
Why, why am I defending C? it’s 2008.. and processors aren’t speeding up anymore (acutally they are lagging up)
And there’s a library, yes right, that exports some symbols (C _cdecl symbols), and using it with a .h file can enable you to write OOP in C. It’s called GObject.
You can write shared libraries that export interfaces, abstract classes and classes for other people to use.
That is, C libraries, but without the burden of manually exporting “C” functions (this is the case with C++) or manually writing a wrapper library that initializes the .NET runtime environment or the JVM.
That means that you can build on existing software and software can build upon you, something other OOP solutions only do “entre eux“, in-house, in their own environment or even only with sources.
Also, GObject solves the name mangling problem, being in C, there is no name mangling. It’s just you that decides the names of the functions.
But how would you do that??
You could start to write boilerplate code like this header (scroll down over it, it’s just an example):
#ifndef __EXAMPLE_H__
#define __EXAMPLE_H__
#include
#include
#include
#include
G_BEGIN_DECLS
#define TYPE_EXAMPLE (example_get_type ())
#define EXAMPLE(obj) (G_TYPE_CHECK_INSTANCE_CAST ((obj), TYPE_EXAMPLE, Example))
#define EXAMPLE_CLASS(klass) (G_TYPE_CHECK_CLASS_CAST ((klass), TYPE_EXAMPLE, ExampleClass))
#define IS_EXAMPLE(obj) (G_TYPE_CHECK_INSTANCE_TYPE ((obj), TYPE_EXAMPLE))
#define IS_EXAMPLE_CLASS(klass) (G_TYPE_CHECK_CLASS_TYPE ((klass), TYPE_EXAMPLE))
#define EXAMPLE_GET_CLASS(obj) (G_TYPE_INSTANCE_GET_CLASS ((obj), TYPE_EXAMPLE, ExampleClass))
typedef struct _Example Example;
typedef struct _ExampleClass ExampleClass;
typedef struct _ExamplePrivate ExamplePrivate;
struct _Example {
GObject parent_instance;
ExamplePrivate * priv;
char* myfield;
};
struct _ExampleClass {
GObjectClass parent_class;
void (*myfunction) (Example* self);
};
void example_myfunction (Example* self);
Example* example_new (void);
char* example_get_myproperty (Example* self);
void example_set_myproperty (Example* self, const char* value);
GType example_get_type (void);
G_END_DECLS
#endif
and this .c file:
#include "Example.h"
#include
struct _ExamplePrivate {
char* _myproperty;
};
#define EXAMPLE_GET_PRIVATE(o) (G_TYPE_INSTANCE_GET_PRIVATE ((o), TYPE_EXAMPLE, ExamplePrivate))
enum {
EXAMPLE_DUMMY_PROPERTY,
EXAMPLE_MYPROPERTY
};
static void example_real_myfunction (Example* self);
static gpointer example_parent_class = NULL;
static void example_dispose (GObject * obj);
static void example_real_myfunction (Example* self) {
g_return_if_fail (IS_EXAMPLE (self));
fprintf (stdout, "myfunction got called\n");
}
void example_myfunction (Example* self) {
EXAMPLE_GET_CLASS (self)->myfunction (self);
}
Example* example_new (void) {
Example * self;
self = g_object_newv (TYPE_EXAMPLE, 0, NULL);
return self;
}
char* example_get_myproperty (Example* self) {
g_return_val_if_fail (IS_EXAMPLE (self), NULL);
return self->priv->_myproperty;
}
void example_set_myproperty (Example* self, const char* value) {
char* _tmp2;
const char* _tmp1;
g_return_if_fail (IS_EXAMPLE (self));
_tmp2 = NULL;
_tmp1 = NULL;
self->priv->_myproperty = (_tmp2 = (_tmp1 = value, (_tmp1 == NULL ? NULL : g_strdup (_tmp1))), (self->priv->_myproperty = (g_free (self->priv->_myproperty), NULL)), _tmp2);
}
static void example_get_property (GObject * object, guint property_id, GValue * value, GParamSpec * pspec) {
Example * self;
self = EXAMPLE (object);
switch (property_id) {
case EXAMPLE_MYPROPERTY:
g_value_set_string (value, example_get_myproperty (self));
break;
default:
G_OBJECT_WARN_INVALID_PROPERTY_ID (object, property_id, pspec);
break;
}
}
static void example_set_property (GObject * object, guint property_id, const GValue * value, GParamSpec * pspec) {
Example * self;
self = EXAMPLE (object);
switch (property_id) {
case EXAMPLE_MYPROPERTY:
example_set_myproperty (self, g_value_get_string (value));
break;
default:
G_OBJECT_WARN_INVALID_PROPERTY_ID (object, property_id, pspec);
break;
}
}
static void example_class_init (ExampleClass * klass) {
example_parent_class = g_type_class_peek_parent (klass);
g_type_class_add_private (klass, sizeof (ExamplePrivate));
G_OBJECT_CLASS (klass)->get_property = example_get_property;
G_OBJECT_CLASS (klass)->set_property = example_set_property;
G_OBJECT_CLASS (klass)->dispose = example_dispose;
EXAMPLE_CLASS (klass)->myfunction = example_real_myfunction;
g_object_class_install_property (G_OBJECT_CLASS (klass), EXAMPLE_MYPROPERTY, g_param_spec_string ("myproperty", "myproperty", "myproperty", NULL, G_PARAM_STATIC_NAME | G_PARAM_STATIC_NICK | G_PARAM_STATIC_BLURB | G_PARAM_READABLE | G_PARAM_WRITABLE));
}
static void example_init (Example * self) {
self->priv = EXAMPLE_GET_PRIVATE (self);
}
static void example_dispose (GObject * obj) {
Example * self;
self = EXAMPLE (obj);
(self->myfield = (g_free (self->myfield), NULL));
(self->priv->_myproperty = (g_free (self->priv->_myproperty), NULL));
G_OBJECT_CLASS (example_parent_class)->dispose (obj);
}
GType example_get_type (void) {
static GType example_type_id = 0;
if (G_UNLIKELY (example_type_id == 0)) {
static const GTypeInfo g_define_type_info = { sizeof (ExampleClass), (GBaseInitFunc) NULL, (GBaseFinalizeFunc) NULL, (GClassInitFunc) example_class_init, (GClassFinalizeFunc) NULL, NULL, sizeof (Example), 0, (GInstanceInitFunc) example_init };
example_type_id = g_type_register_static (G_TYPE_OBJECT, "Example", &g_define_type_info, 0);
}
return example_type_id;
}
But you may find it better to write the same boilerplate in Vala:
using GLib;
public class Example: GLib.Object {
public string myfield;
public string myproperty { get; set;}
public virtual void myfunction(){ stdout.printf(“myfunction got called\n”); }
}
So this is it: Vala is yet another C preprocessor (just like C++ was).Vala has a C#-like syntax and it spills out GObject code. That means that you can:
- export clasess, interfaces from a shared library (so/dll) or (re)use existing classes/interfaces from another library
- use your existing (optimized) compiler that’s been around for 15 years and it’s tested
- forget about allocation/deallocation – Vala .ref ()’s and .unref ()’s for you
- use lambda expressions
- use existing GObject signals and properties painlessly
- use a string class that can be passed/received to/from existing API functions unchanged (no ->c_str () needed)
- fine tune your Vala object methods with [Import]s from manually crafted C sources
- define a VAPI file for existing libraries so that you can use them directly as objects from Vala (they don’t need to be GObject libraries)
- oh, and you can make some Generic programming. Just to make the collections work;)
Vala – the best thing since sliced bread? You decide: check out the tutorial:)
Think Big [drawing]
You know there is a reason behind people still using e-mail (instead of instant messaging), and other people try pushing REST on us?
Well, e-mail and URLs work even on a connection which has a Big Lag. Or latency. You can write an e-mail now and check for the answer an hour later.
And RESTful sites have the advantage of being cacheable (for read only, of course). So you can run httrack on them and browse them later, or better, put an HTTP cache server in your LAN.
In other words: did you know that the Moon is 384 thousands km away from us? That’s about 1.2 seconds for the light to travel..The distance of Mars from our planet has a minimum 55 millions of kilometers and a maximum of 376 millions.
Thats between 3 and 20 minutes “one way lag” ! Now let me tell you something while I clicked that AJAX combobox…

None of the Science-Fiction books I read featured “out in space” Internet .
Think Big Lag!
